Day 5 finds us on an island, planting seeds with a twist. Check out the full description of the problem, and try it yourself!
You are given an almanac consisting of a list of seeds, each identified by a number, and a set of rules. Your almanac starts with a list of seeds, each identified by a number:
seeds: 79 14 55 13As any gardener will tell you, seeds need a lot of things to go right for them to germinate (despite the fact that plants seem to grow quite well in cracks in the road).
Anyway, today’s problem recognizes the different aspects surrounding successful seed surrogacy. The rules in your almanac outline:
- what soil to use with each seed
- what fertilizer to use with each soil type
- what water to use with each fertilizer type
- what light to use with each water type
- what temperature to use with each light type
- what humidity to use with each temperature type
- what location to use for each humidity type
All of these different aspects, like the seeds, are identified by a number.
Each aspect takes a specific source number and transforms it into a destination number. So for any given seed number, you are told how to find the right soil number for it. Once you have the soil number, you can find the right fertilizer number, and so on.
And to make the input file a manageable size, these transformations are given in the form of mappings from source to destination.
Here’s a sample seed to soil map — all the other maps in the almanac look like this:
seed-to-soil map:
50 98 2
52 50 48These maps consist of a set of rules which tell you how to convert a number from the source category seed to the destination category soil. Each rule in the map follows the same pattern of three numbers:
- The first is the start of the destination range
- The second is the start of the source range
- The last is the length of the range
So for the first rule in the soil-to-seed map, the numbers 50 98 2 indicate that any seeds with the numbers 98..99 map to the soil range 50..51.
For seed 79, this rule does not apply, so you move on to the next rule, which maps seeds in the range 50..97 to the destination range 52..99. This changes the seed number from 79 to 81. Similarly, the seed 55 becomes 57 by this rule.
What if you have a seed not covered by any of the maps? Those remain unchanged, and you can move to the next may. The seeds 14 and 13 fit this category, so you would move to the soil-to-fertilizer map with the soil numbers 81 14 57 13, and start applying rules to them.
One you’ve processed all the seeds through all the maps, you’ll have a set of location numbers. Find the lowest one, and you’re done. In the sample, the lowest location is 35 (follow seed 13 through all the maps), but will be much larger for the real input.
Approach
The first problem I saw was parsing each map.
My approach implements a struct which reads and parses each rule range in each map. The first step was being able to read the map lines in, so FromStr to the rescue:
pub struct MapLine{
pub source_start: u64,
pub source_end: u64,
pub dest_start: u64,
}
impl FromStr for MapLine{
type Err = MapParseError;
fn from_str(s: &str) -> Result<Self, Self::Err> {
let split: Vec<_> = s
.split_whitespace()
.into_iter()
.map(|i| i.parse::<u64>())
.collect::<Result<Vec<u64>, std::num::ParseIntError>>()?;
if split.len() != 3 {
return Err(MapParseError::FormatError(s.to_string()));
}
Ok(MapLine {
source_start: split[1],
source_end: split[1]+split[2]-1,
dest_start: split[0],
})
}
}This way, I can use MapLine::from_str(line) to parse each line automagically.
Note that I didn’t magically figure this out on my own — my thanks go to my colleague Yuri Gorokov for the help with the error handling here. Asking for help from an expert is part of how I learn.
Once I had the maps defined, I defined a couple of mapping methods to help convert source numbers to destination numbers:
impl MapLine{
pub fn source_in_range(&self, source: u64) -> bool{
source >= self.source_start && source <= self.source_end
}
pub fn dest_from_source(&self, source: u64) -> u64{
if !self.source_in_range(source){
source
} else {
self.dest_start + source - self.source_start
}
}
}The dest_from_source() automatically handles the case where the source number isn’t in range, so I don’t need to check that in the main program.
I stored the set of maps in a Vec<MapLine>, and stored the entire almanac in a HashMap<String, Vec<MapLine>>, where the String key was the name of the map ('soil-to-seed', and so on).
From here, it was a relatively simple matter to go through each map in order, apply each seed to each map, and find the lowest final number:
let map_order = [
"seed-to-soil map:".to_string(),
"soil-to-fertilizer map:".to_string(),
"fertilizer-to-water map:".to_string(),
"water-to-light map:".to_string(),
"light-to-temperature map:".to_string(),
"temperature-to-humidity map:".to_string(),
"humidity-to-location map:".to_string()
];
// Now we can process our seeds
let mut lowest = u64::MAX;
for mut seed in seeds.unwrap(){
// Find each map in order
for next_map_name in &map_order{
let current_map = almanac.get(&next_map_name).unwrap();
// We modify the seed based on each entry in the map
for current_map_line in current_map{
if current_map_line.source_in_range(seed){
seed = current_map_line.dest_from_source(seed);
break;
}
}
}
if seed < lowest{
lowest = seed
}
}We return lowest, and Bob, as they say, is your uncle.
This might have been more efficient if I looped over the maps in the outer loop, then the seeds in the inner, but I’m not sure without profiling it. In any case, this ran fast enough I wasn’t at all concerned.
Part 2
This was a little trickier, as all parts 2 are.
The complication added was that we misinterpreted the seed numbers in part 1. The seed numbers aren’t individual seeds, but ranges of seed numbers. Interpreted in pairs, the first number is the start of a range, and the second is the number of seeds in that range.
This means the sample seed numbers 79 14 55 13 now represent two ranges of seeds: the 14 seeds in the range 79..92, and the 13 seeds in the range 55..67.
Your task now is the find the lowest location for any of the seeds in the ranges given.
Analysis
As usual, simply applying part 1 code won’t work in a reasonable amount of time. For my real input, just the first range had 4.4 million seeds in it, and my CPU fans were struggling to keep up with the heat removal.
I needed to think differently.
Looking at the description, I keyed into the word range. Maybe this was solvable if I thought in terms of ranges of seeds instead of individual seeds? How can we use this to make our lives simpler?
Ranges
Let’s assume first that we have a rule which remaps seed numbers in the source range 10..20.
Let’s look at valid seed ranges which we may see when applying this rule. We’ll start with the trivial examples — in the images below, any seed numbers in green are seeds which apply to the rule, and any numbers in red do not apply.

In the image above:
- The seed range
5..8doesn’t apply, as it is too low. - The seed range
23..30similarly doesn’t apply, as it is too high. - The seed range
12..18applies, as it is completely within the rule range.
In the first two cases, the seed range remains unchanged, as the rule doesn’t apply.
In the last case, the rule applies to the entire range. This means we can treat the start and end of the range as individual seed numbers, remapping them to get a new destination range.
So far, so good, but these are trivial cases. Let’s look at three more involved ranges:
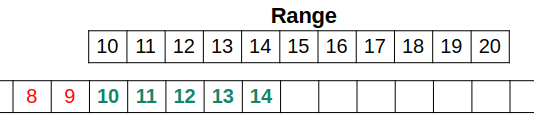
The seed range 8..14 overlaps the beginning of the rule, and is partially mapped:
- The seeds in
8..9are not applicable to this rule. - The seeds in
10..14are applicable, and should be remapped.
How do you handle this? By splitting the range into two separate ranges: 8..9 and 10..14. Now you have two ranges to deal with instead of one, but they are trivial cases which are easily handled.

The seed range 16..22 overlaps the end of the rule, and also partially maps:
- The seeds in
16..20are applicable, and should be remapped. - The seed in
21.22are not applicable to this rule.
As above, you split this range into two separate ranges(16..20 and 21..22), applying the rule to the first one.

The seed range 6..24 overlaps both ends of the rule, and partially maps as well:
- The seeds in
6..9are not applicable to this rule. - The seeds in
10..20are applicable and should be remapped. - The seed in
21..24are not applicable.
This range needs to split into three new ranges as shown above, remapping the only one which is applicable.
However, there is another matter to deal with.
State Machine
In part one, there were only a fixed amount of source numbers to deal with. Now, we are potentially creating new ranges, and we need to figure out what to do with them.
When a source range is split, the new ranges which are not applicable to the current rule need to be passed on to the next rule in the current map. Any ranges which are applicable to, and therefore changed by, the current rule should wait for the next map to be reprocessed.
This means any given range can be in one of three states:
- Unprocessed by the current rule.
- Processed and modified by the current rule.
- Processed but unchanged by the current rule.
Each state has it’s own handling as well:
- Anything unprocessed get run through the current rule.
- Modified ranges aren’t reprocessed, but wait until the next map is being run.
- Unchanged ranges are added to the unprocessed list for the next rule in the current map to be applied.
Once all the rules in a map have been processed, any ranges in the unchanged and modified lists are combined into a new unprocessed list for the next map.
Finally, after every range is processed through all the maps, they will all be in the unprocessed list. From here it’s a matter of scanning them all and finding the range with the smallest start. This is the lowest location number and the answer to part 2.
As always, my code is here — comments and pull requests are always read and reviewed.
Summary
Day Five problems are usually a bit of a test — in my experience, they are the first problems that require some more in depth analysis to get to an answer, rather than just relying on past experience. This was no exception.
Getting to the right way to think about today’s problem was just the first step. Once there, I had to identify and handle all edge cases, and I think I could find a better way to represent all the data to make the code easier to read and write. However, even so, it worked and I’m happy with it so far.